

2年前に購入したGoogle AIY Voice Kitに最近カメラモジュールを追加しました。さらに、Google Cloud Vision APIを使った画像認識プログラムにトライしてみました。その過程はこちらの記事で紹介しています。

さて実際に、カメラの前にモノをかざしてどの程度認識するのか見てみましょう。机の周りを見渡して使えそうなものはないかしら…
ラズパイのカメラモジュールのパッケージ

まずはラズパイのカメラモジュールのパッケージ。あれは何?(What is that?)と聞くと、

音声とともにテキストで、製品、テキスト、技術、電子機器、という返答が帰ってきました。音声で読み上げてくれるのは良いですね。返答はこのような単語の羅列で返ってくるのです。
さらに、同じ映像に対して、それ読める?(Can you read that?)と聞いたところ…
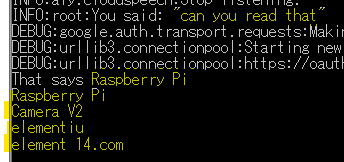
パッケージに書かれているテキストをそれなりに正確に読み取ってくれました。element14はelement iuと読み取ったようですが、それは仕方ないですかね。
ソニーのワイヤレスヘッドフォン

次に何か認識してくれるロゴはないかなと思って、手元のソニーのワイヤレスヘッドフォンを試してみました。そのロゴは何?(What logo is that?)と聞いてみたところ…
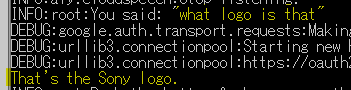
ソニーのロゴよ。と分かってくれました。メイドインジャパン。ちょっと嬉しい。
ロクシタンのボディミルク

電子機器系だけではなくて、化粧品系はどうだろうと思い、ロクシタンのボディミルクで実験。
ロゴは認識してくれず、あれは何?(What is that?)と聞くと…

製品、ボトル、プラスチックボトル、水、手(これは私の手のことでしょうか)、液剤、と出てきました。まぁ、間違ってはおりません。
さらに、それ読める(Can you read that?)と聞いたところ…
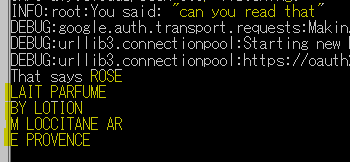
Lait Parfumeとかフランス語なのですが、さすがアルファベット。それなりに認識してくれました。MLがMになっていたり、En ProvenceはE Provenceになっていますがね。
日本語の絵本
次は日本語の絵本です。息子のお絵かきの本を認識させてみました。

日本語の読み取りは注意
すると最初は…
UnicodeEncodeError: 'latin-1' codec can't encode characters in position 14-20: ordinal not in range(256)
のように出てきてしまい、エラーでプログラムが終了してしまいました。
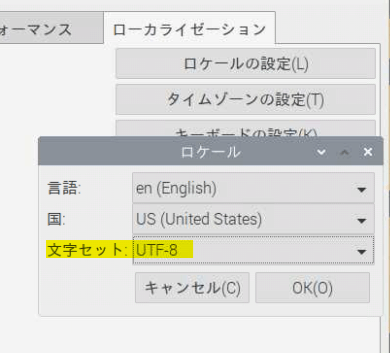
最初は日本語の読み取りは無理なのかしらと思ったのですが、ラズパイの言語設定のエンコードをUTF-8にしたら大丈夫になりました。
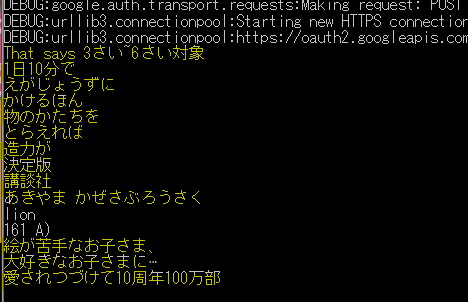
ばっちり日本語も認識してくれています。
アニマトロニクス(フレディ)のフィギュア

ついでに息子のお気に入りのFNAFのフレディのフィギュアはどうだろうと試してみると…

さすがにクラウドビジョンといえど、フレディは知らなかったもよう。ですが、オモチャ、フィギュア、アクションフィギュア、アニメーション、茶色、技術、3Dモデリング、という返答はそれなりに的を得ていると言わざるを得ませんね。
トランスフォーマーのおもちゃ
もう少しメジャーなキャラクターなら認識してくれるかしら、と思い、家の中を探したところ、息子のトランスフォーマーはオプティマスプライムのおもちゃを発見。これならどうかしら。

それは何(What is that?)と聞いたところ…

アクションフィギュア、オモチャ、メカ、フィクションのキャラ、トランスフォーマー、と出てきました。トランスフォーマーが出てきたぞ。やはり認識できるんですねぇ。スゴイ!さすが!Google Cloud Vision と思いました。
日本語化は別途進行中
ただし、今回のプログラム、すべて受け答えは英語です(^^;。今回使用したプログラムを日本語化できないかと検討したのですが、AIYのVoiceに使われているtts.pyというファイルと、Google Vision APIのアウトプットのテキストが日本語に対応していないんですよね。だから、音声で返ってくる部分で日本語が抜けてしまうし、画像認識で返ってくる単語も英語になってしまいます。
というわけで、日本語版で同等のものを作るなら、今回トライしたプログラムを翻訳するよりも、別モノを作ってしまった方が良いのではと思っており、現在トライ中です。また進展があればブログで報告いたします。
コメント